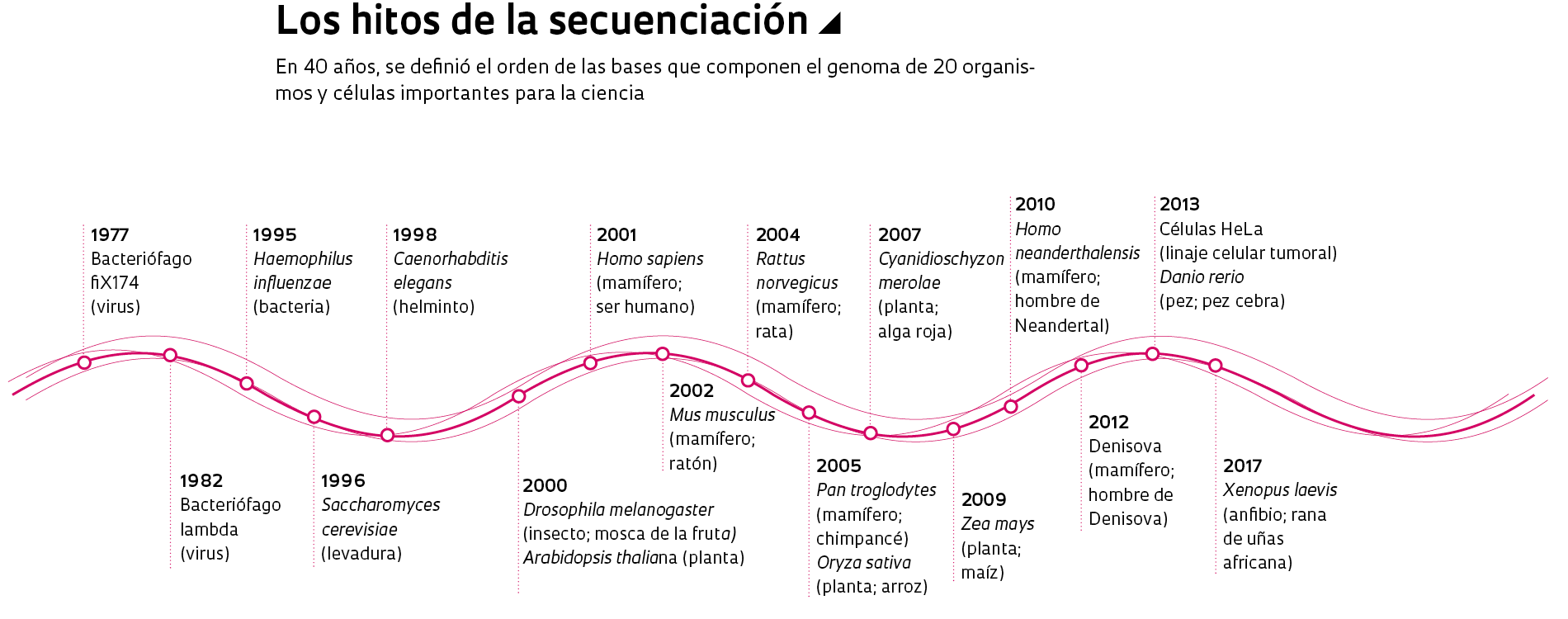
La revista siguió la evolución de los proyectos de secuenciación que mejoraron el diagnóstico de enfermedades y condujeron al desarrollo de fármacos innovadores
Alexandre Affonso
A partir de este mes, ocho centros del sistema público de salud brasileño especializados en enfermedades raras tendrán disponibles para todos los niños con atrofia muscular espinal (AME) el primer medicamento capaz de mitigar los síntomas de ese trastorno de origen genético. Este tipo de atrofia lleva a la pérdida progresiva de la fuerza muscular y, en los casos graves, a una muerte precoz. El fármaco, cuya denominación es nusinersen, fue aprobado para su uso clínico en Estados Unidos en 2016 y en Brasil en 2017. Lo comercializa el laboratorio estadounidense Biogen bajo el nombre de Spinraza y mejoró la habilidad motora en el 40% de los niños tratados, según datos publicados en 2017 en la revista científica New England Journal of Medicine. El medicamento modifica el funcionamiento de un gen y eleva la producción de la proteína SMN, esencial para la supervivencia de las células de la médula espinal que transmiten las órdenes del cerebro a los músculos.
El nusinersen, que se inyecta por debajo de las membranas que protegen la médula espinal, es uno de los medicamentos más caros del mundo. Cuando salió a la venta, las seis dosis que se aplican durante el primer año de tratamiento costaban 750 mil dólares en Estados Unidos. A partir del segundo año, la cantidad de aplicaciones y el costo del tratamiento, que es para toda la vida, caen a la mitad. En Brasil, el medicamento figura en el vademécum con el listado que ofrece el Sistema Único de Salud (SUS) desde el mes de abril, para aquellos casos que se manifiestan durante los primeros seis meses de vida y, a partir de ahora, también para los que lo hacen después de eso. En Brasil nacen anualmente entre 300 y 400 bebés con AME.
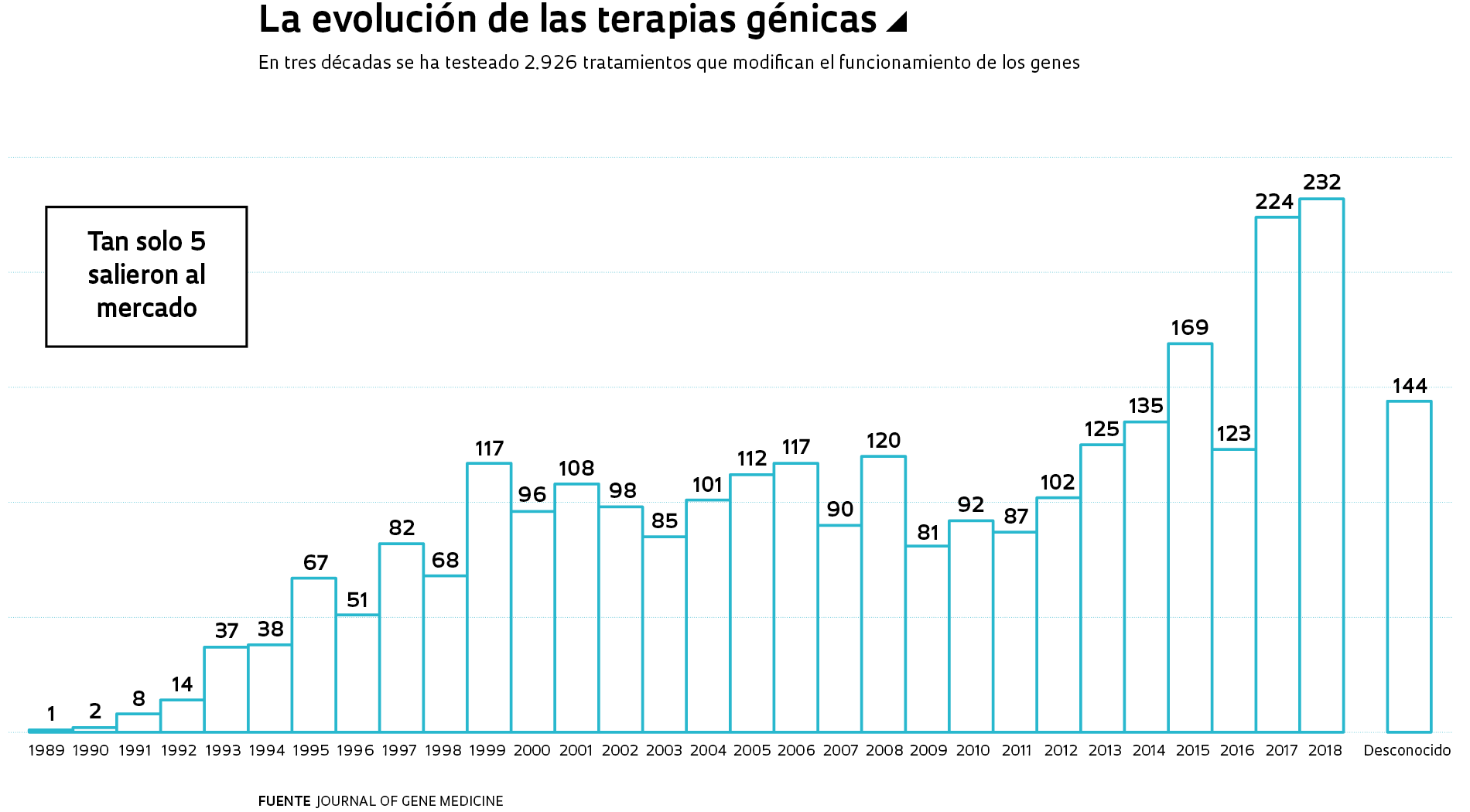
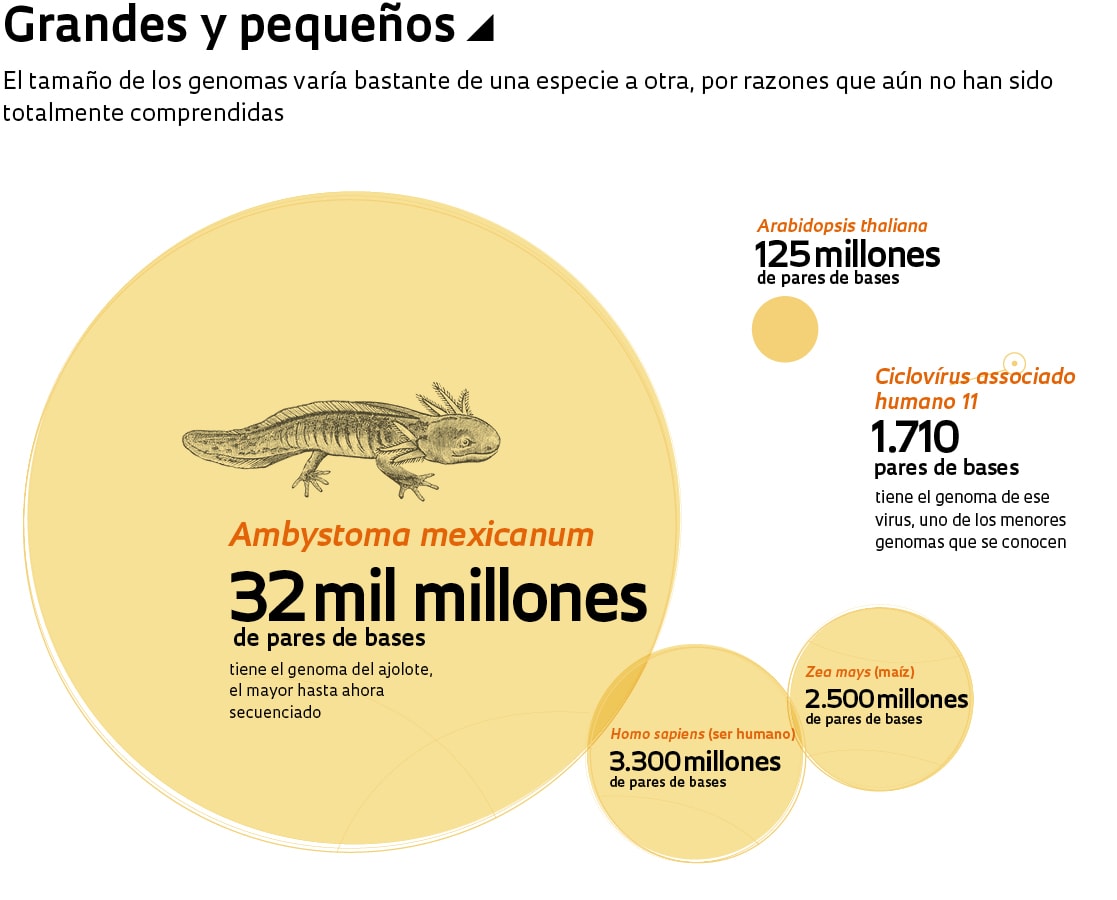
El nusinersen forma parte de un nuevo tipo de compuestos. Estos medicamentos surgen a partir de la secuenciación del genoma humano, que transformó la biología molecular y fue un tema recurrente en las páginas de Pesquisa FAPESP durante sus 20 años de existencia. La revista publicó al menos 10 tapas sobre los diversos proyectos genoma y sus resultados, además de decenas de reportajes menores. La especificación del orden de los 3.300 millones de bases nitrogenadas (adenina, A; timina, T; citosina, C, y guanina, G) del genoma humano abrió el camino para análisis más rápidos y precisos de sus genes, algo que, a su vez, perfeccionó y abarató el diagnóstico de las enfermedades genéticas. También condujeron a tratamientos innovadores, algunos de ellos con potencial de cura. Sin embargo, estas nuevas terapias aún tienen un acceso limitado debido a lo exorbitante de su costo.
“La secuenciación del genoma humano posibilitó un avance importante en el diagnóstico de las enfermedades raras”, dice la genetista Lygia da Veiga Pereira, de la Universidad de São Paulo (USP). Se trata de enfermedades causadas por alteraciones en un único gen (monogénicas) y generalmente graves. En forma aislada, cada una de ellas acomete a un porcentaje que varía de una por cada mil a una de cada 100 mil personas. Si se las suma, afectan a casi un 6% de la población mundial, un porcentaje similar al que se ve afectado por la diabetes (un 8,5%). Hacia el año 2000, cuando un consorcio público internacional de secuenciación competía con la empresa liderada por el genetista estadounidense John Craig Venter para concluir la tarea de leer y ordenar las letras químicas del genoma humano, ya se conocían 1.900 enfermedades monogénicas. Hoy en día están mapeadas las alteraciones en 4.147 genes asociados a 6.499 dolencias, según consta en la base Online Mendelian Inheritance in Man (Omim).
El avance en las técnicas de secuenciación y la evolución de la bioinformática permitieron comparar el genoma de individuos sanos con el de pacientes con diversas enfermedades e identificar la causa de las enfermedades monogénicas, algo que aún no pudo determinarse para los trastornos que involucran a varios genes (poligénicas) que son más complejos. “Este conocimiento fue esencial para mejorar la identificación y el tratamiento, aparte de la prevención, que se realiza por medio del asesoramiento genético de las familias”, explica la genetista Mayana Zatz, coordinadora del Centro de Investigación sobre el Genoma Humano y Células Madre (CEGH-CEL) de la USP, uno de los Centros de Investigación, Innovación y Difusión (Cepid) financiados por la FAPESP. En el CEGH-CEL, un único test detecta alteraciones en los genes asociados a casi 6.700 enfermedades (neuromusculares, cánceres hereditarios, autismo y otras).
La identificación de la causa de las enfermedades genéticas mejora la calidad de vida porque le permite al médico seleccionar los remedios más eficientes para atenuar los síntomas y evitar aquellos medicamentos que los agravan. También previene a familiares y cuidadores ante la evolución de la enfermedad. Incluso hay un beneficio imponderable, recuerda la médica genetista Iscia Lopes Cendes, coordinadora del Laboratorio de Genética Molecular de la Universidad de Campinas (Unicamp) e investigadora del Brainn, otro Cepid financiado por la FAPESP. “Los test genéticos generalmente brindan un diagnóstico definitivo para esas enfermedades graves y aplacan la angustia de los padres”, explica.
Cuando se publicó la primera versión del genoma humano, en 2001, afloró un optimismo exagerado de muchos científicos, un alborozo que generó repercusiones en los medios de comunicación y despertó en el seno de la población anhelos difíciles de ser atendidos. Por entonces, el genetista estadounidense Francis Collins, quien en esa época era el director del Instituto Nacional de Investigación del Genoma Humano (NHGRI, por sus siglas en inglés) de Estados Unidos, quien coordinó el consorcio público de secuenciación, comparó al genoma con un libro que narraría la trayectoria de nuestra especie en el tiempo. Y añadió: “Es un libro de medicina transformador, con ideas que dotarán a los prestadores de servicios de salud de poderes inmensos para tratar, prevenir y curar enfermedades”.
Ese tono hiperbólico contrastó con la mesura de los artículos científicos que informaban sobre el suceso, uno publicado el 15 de noviembre de 2001 en la revista Nature a cargo del consorcio integrado por Collins y otro en Science, al día siguiente, del equipo de Venter. Al hablarle a sus pares, el grupo de Collins fue cauteloso. Afirmó que a largo plazo habría consecuencias para la medicina y concluyó el artículo diciendo: “Debemos trazar expectativas realistas porque los beneficios más importantes no se obtendrán de la noche a la mañana”.
En la Science, Venter y sus colaboradores escribieron: “La secuencia tan solo representa el primer nivel de comprensión del genoma. Todos los genes y sus elementos de control deben identificarse; sus funciones, ya sea en conjunto o en forma aislada deben definirse; las variaciones en la secuencia deberían ser descritas en todo el mundo, y debe determinarse la relación entre las variaciones en el genoma y las características fenotípicas [observables] específicas”.
La ciencia, como ellos ya sabían, no es rápida. “Al cabo de estos casi 20 años ha habido mucho progreso, pero aún no disponemos de las aplicaciones que muchos imaginaban”, dice Cendes.
En la actualidad se conocen 4.147 genes asociados a 6.499 enfermedades
En los consultorios Los avances en las tecnologías de secuenciación y en las estrategias de análisis de datos a partir de la bioinformática fueron esenciales para que la medicina, casi dos décadas más tarde, comenzara a utilizar los conocimientos de la genómica en la práctica clínica. “Solo recientemente algunas áreas médicas pasaron de una postura contemplativa a otra más activa”, comenta el neurólogo infantil Fernando Kok, investigador de la Facultad de Medicina de la USP (FM-USP) y director médico de Mendelics, una empresa de diagnósticos genéticos personalizados. Para él, se estaría cerca del surgimiento de una oleada de terapias génicas, cuyo acceso será acotado debido a su costo. “La ampliación de su acceso será un problema para los gestores del área de la salud”, anticipa.
Uno de los motores del progreso en la genómica fue el perfeccionamiento de la tecnología de secuenciación. A mediados de la década de 1970, cuando Allan Maxam y Walter Gilbert, en Estados Unidos, y Frederick Sanger y Alan Coulson, en Inglaterra, desarrollaron las dos primeras estrategias de secuenciación del ADN, el proceso era lento y laborioso. Gilbert y Sanger compartieron el Nobel de Química de 1980 con el bioquímico Paul Berg. Se demoraba un día para identificar el orden de algunas centenas de bases de ADN. Solo una década después surgieron los dispositivos automáticos, que empleaban el método de Sanger y que se los utilizó en el Proyecto Genoma Humano.
Con esta técnica, de mayor precisión, se realiza la secuenciación de un solo tramo corto de ADN por vez, de hasta 900 bases. En la misma se producen copias con una cantidad creciente (1, 2, 3…) de bases. Tan solo se le agrega una base (A, C, T o G) a cada copia, y la última base se marca siempre con un colorante fluorescente (verde para A; azul para C; rojo para T, y verde para G). Una vez finalizada la producción de las copias, se las separa según su tamaño. Al conocerse la última base de cada copia, puede restablecerse la secuencia original. El método de Sanger todavía se emplea actualmente para secuenciar moléculas aisladas del ADN, aunque ha reemplazado en la mayor parte de las aplicaciones por una técnica más rápida y barata, la secuenciación de nueva generación (NGS, en inglés), que identifica el orden de las bases de millones de moléculas en forma simultánea. Aparte de esas dos técnicas, adoptadas en los laboratorios clínicos, existe una tercera que se utiliza en el ámbito de la investigación científica: la secuenciación en tiempo real de molécula única (SMRT, por sus siglas en inglés), un procedimiento mediante el cual una fuente de luz láser ilumina cada base marcada con un colorante fluorescente a medida que se la agrega a la cinta de ADN que se está copiando.
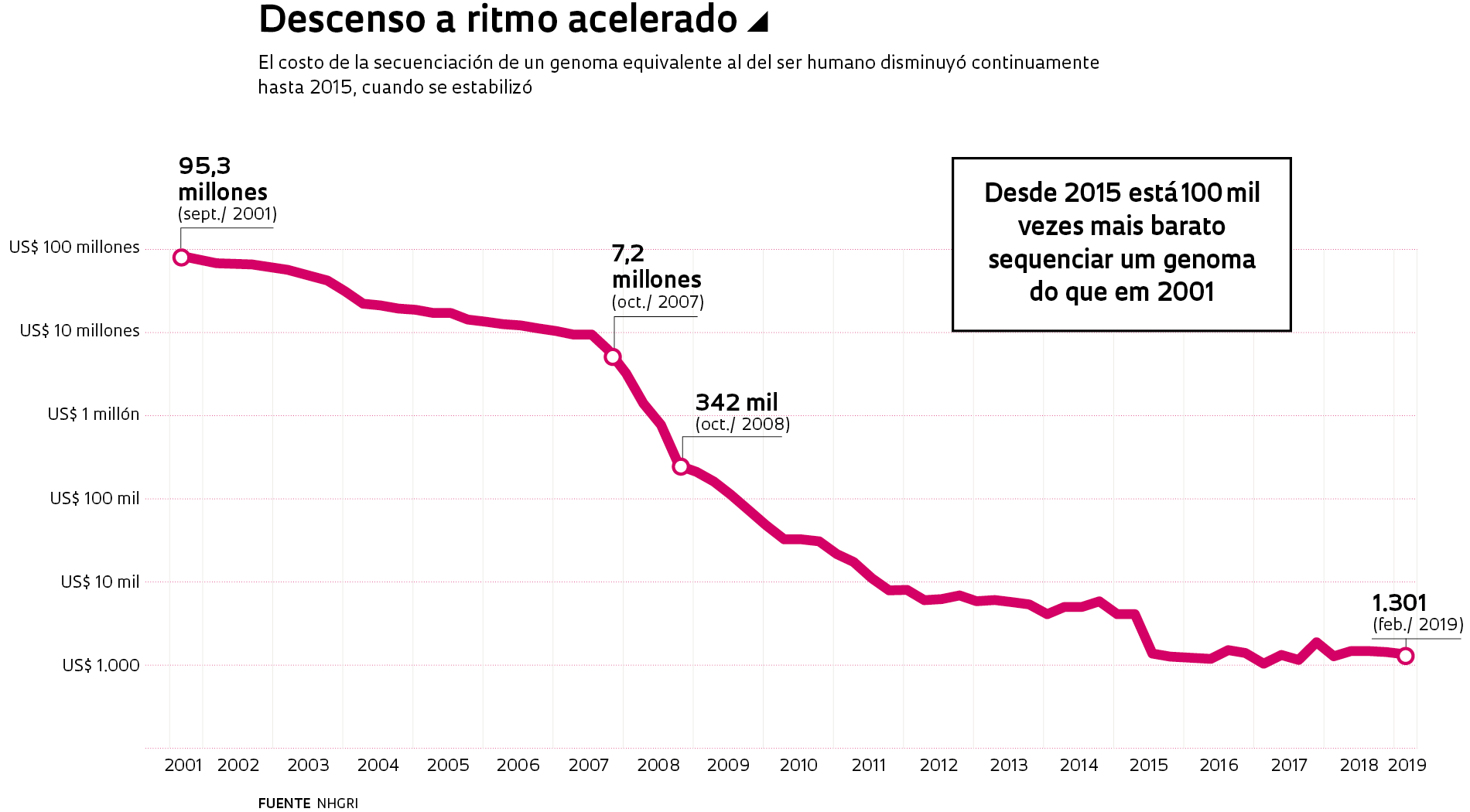
El costo del procedimiento se redujo de 100 millones de dólares en 2001 a alrededor de 1.000 dólares en 2015, según cálculos del NHGRI (vea el gráfico arriba). Este valor se ha estabilizado, aunque las empresas trabajan para disminuir el precio de la secuenciación del genoma o, al menos, del exoma, que es el segmento que contiene los 24 mil genes que codifican proteínas, a un monto estipulado en cientos de dólares.
“Fue necesario llegar al punto en que las técnicas se abarataran mucho y volvernos lo suficientemente buenos en la interpretación de los datos para que esta tecnología estuviera disponible en la práctica médica”, comenta Cendes. Un trabajo bajo su supervisión y la de la médica genetista Antonia Marques de Faria, también de la Unicamp, sirvió como base para la aprobación, en marzo de este año, de la incorporación de un nuevo test genético al SUS para diagnosticar la discapacidad intelectual: la secuenciación de exomas.
Con diferentes manifestaciones clínicas, la discapacidad intelectual está considerada como un conjunto de enfermedades raras cuyo diagnóstico clínico resulta difícil. Sus diversas formas, sumadas, afectan a entre el 1% y el 2% de la población y en sus diversos grados dificultan el aprendizaje, la habilidad de interacción social y la capacidad de cuidado personal. El diagnóstico actual en el SUS se realiza mediante un test de cariotipo (un análisis de los cromosomas, las estructuras orgánicas que contienen los genes) y por microarrays −chips de ADN o ARN−, una técnica con la cual se analizan las repeticiones en el genoma y que aún se encuentra poco disponible. La primera identifica la causa en el 3% de los casos y la segunda, hasta en un 20% de los mismos. En tanto, el análisis del exoma funciona en casi el 40% de los casos. En cuanto a la relación costo-beneficio, la alternativa del exoma parece valer la pena, según se desprende de un estudio llevado a cabo por Joana Prota, alumna de doctorado bajo la dirección de las investigadoras de la Unicamp.
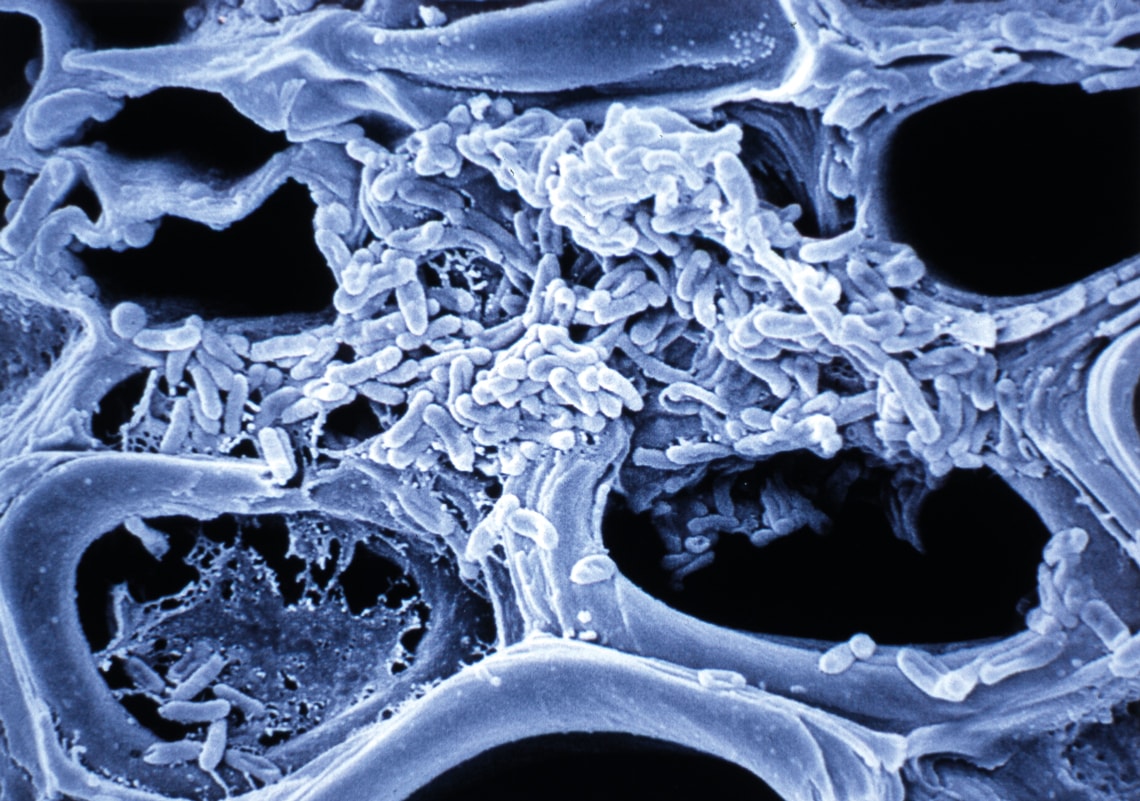
Vasos del tallo de un naranjo bloqueados por una colonia de la bacteria Xyllela fastidiosa, el primer fitopatógeno con su genoma secuenciado
Enfermedades comunes Si bien ha logrado un avance en la determinación de las causas de las enfermedades raras, la genómica todavía deja mucho que desear en lo que respecta a las enfermedades más comunes, tales como la diabetes, los problemas cardiovasculares, los trastornos psiquiátricos y muchas formas de cáncer, importantes desde el punto de vista de la salud pública pues afectan a una gran cantidad de personas. Se trata de enfermedades complejas y multifactoriales: son el resultado de la acción de decenas y centenas de genes, que interactúan entre sí y con el ambiente. Por esta razón, hasta ahora no se ha encontrado un gen que por sí solo cumpla un papel importante en el surgimiento de la hipertensión arterial, un problema que afecta a alrededor de una tercera parte de la población adulta en todo el mundo. Las formas derivadas de la alteración de un único gen son raras. Lo propio sucede con la diabetes, los trastornos psiquiátricos y diversos tipos de cáncer.
En las enfermedades complejas, la incidencia de cada gen es menor. Solo es posible calcular el efecto de cada uno comparando un gran número de genomas, tal como se está empezando a hacer en Inglaterra, Estados Unidos y China, donde hay proyectos para secuenciar el material genético de hasta un millón de personas. De cualquier modo, puede que lo que se encuentre solamente sirva para las poblaciones europeas o asiáticas. En un artículo que salió publicado en marzo de este año en la revista Cell, el genetista Giorgio Sirugo, de la Universidad de Pensilvania, y otros dos colaboradores de Estados Unidos, afirmaron que los estudios de amplia asociación del genoma, destinados a identificar variantes asociadas a rasgos complejos o al riesgo de desarrollo de enfermedades, están concentrados en poblaciones acotadas: el 52% de ellos se realizó con europeos y el 21% con asiáticos. Según los investigadores, el estudio de grupos con otros orígenes es de importancia porque “los modelos de variación genética entre poblaciones pueden incidir sobre el riesgo de desarrollo de enfermedades y en la eficacia y la seguridad de los tratamientos”.
En Brasil, los estudios de evaluación genómica de la población aún son raros. En el CEGH-CEL, el equipo de Zatz efectuó el análisis del exoma de aproximadamente 1.500 paulistas mayores de 60 años en busca de variaciones génicas protectoras, y la Brazilian Initiative on Precision Medicine (Bipmed), coordinada por Cendes, fue pionera poniendo a disposición pública los datos genómicos de casi 900 individuos (350 de ellos sanos, en representación de la población en general). En el A.C.Camargo Cancer Center, en São Paulo, los científicos secuenciaron recientemente el genoma de 300 pacientes con cáncer de estómago. En la USP, Lygia Pereira se propone ahora obtener datos de cientos de miles de genomas de brasileños para caracterizar las variaciones genéticas de la población.
Con todo, por ahora los análisis genómicos permiten asociar, a lo sumo, la presencia de determinadas alteraciones genéticas con el riesgo (predisposición) de desarrollar un problema de salud. “La contribución de estos estudios para la diabetes y la obesidad, por ejemplo, aún es pequeña y su potencial a mediano plazo consiste en posibilitar tratamientos más efectivos”, comenta el endocrinólogo experto en enfermedades genéticas Alexander Jorge, de la USP.
Pese a estas limitaciones, la información sobre alteraciones genéticas obtenidas a partir del genoma y de los proyectos subsiguientes han colaborado en el diagnóstico y el tratamiento de muchos de los casi 200 tipos conocidos de cáncer. “En la oncología, las características genéticas de los tumores se están utilizando para identificar el tipo de cáncer y su agresividad. También permiten monitorear la evolución de la enfermedad y la respuesta al tratamiento”, sostiene la genetista Anamaria Camargo, coordinadora del Centro de Oncología Molecular del Instituto Sirio-Libanês de Ensino e Pesquisa (IEP), en São Paulo.
Al igual que Camargo, muchos de los líderes de los principales centros de diagnóstico y tratamiento oncológico de Brasil siguieron de cerca el Proyecto Genoma Humano y adquirieron conocimientos en genómica al participar en los primeros proyectos de secuenciación en el país, organizados y financiados por la FAPESP y por otras instituciones. En 1997, bajo la coordinación de los bioquímicos Andrew Simpson y Fernando Reinach, por entonces del Instituto Ludwig de Investigaciones sobre el Cáncer (LICR, por sus siglas en inglés) y de la USP, respectivamente, y del genetista Paulo Arruda y el bioinformático João Carlos Setubal, de la Unicamp, los equipos de 35 laboratorios paulistas iniciaron la secuenciación del genoma de la bacteria Xyllela fastidiosa, causante de la clorosis variegada de los cítricos (CVC), enfermedad conocida popularmente como “amarelinho” en Brasil, que asolaba la producción en los naranjales paulistas.
“Ese fue un proyecto ideado para brindarles capacitación a los grupos con el objetivo de realizar la secuenciación de genomas, algo que prácticamente era inexistente en el país”, dice el físico José Fernando Perez, por entonces director científico de la Fundación y actualmente presidente del directorio de Recepta Biopharma, una empresa de biotecnología que desarrolla compuestos para el tratamiento del cáncer.
Unos tres años más tarde, los 2,7 millones de bases del genoma de la bacteria habían sido identificados y ordenados. El artículo que mostraba ese resultado fue estampado en la portada de la edición del 13 de julio de 2000 de la revista Nature. En esa época, aún estaba en curso el Proyecto Genoma Humano y tan solo se habían secuenciado los genomas de ocho organismos tomados como modelo por la biología: dos virus, una bacteria, una levadura, un helminto y una planta (lea la página 35). El genoma de la Xyllela fue el primero de un organismo causante de una enfermedad en plantas, con importancia comercial. “Esa fue una instancia en que Brasil demostró que, compitiendo en condiciones de igualdad, produce ciencia de nivel internacional”, dice Simpson, en la actualidad director científico de Orygen Biotecnologia, una empresa farmacéutica que se dedica a la producción de anticuerpos, vacunas y otros medicamentos de origen biológico.
“Durante aquel período, Brasil fue uno de los pocos países capaces de secuenciar el genoma completo de un organismo”, recuerda Reinach, quien ya hace años que se desligó de la universidad y actualmente dirige un fondo de inversión en empresas innovadoras. Desde entonces, se han secuenciado los genomas de casi 19 mil organismos: 3.500 virus, 14.700 bacterias y 400 animales y plantas conformados por una o más células.
En el marco de la concepción del proyecto de la Xyllela, el oncólogo Ricardo Brentani (1937-2011), por ese entonces director de la filial brasileña del LICR, decidió organizar un equipo y participar también en la secuenciación. “Brentani advirtió en la Xyllela una oportunidad para introducir la genómica en la oncología”, relata Emmanuel Dias-Neto, coordinador del Laboratorio de Genómica Médica del A.C.Camargo Cancer Center, del cual Brentani también era director. Allí, al igual que en el IEP, genetistas y otros investigadores del área de la ciencia básica trabajan en colaboración con el cuerpo clínico del hospital utilizando información genética de los tumores para encauzar el tratamiento y registrar la reaparición de tumores antes de que puedan detectarse en los estudios por imágenes.
En 1998, cuando estaba por concluirse la secuenciación del genoma de la Xyllela, algunos laboratorios que ya participaban en el proyecto y otros que aún no formaban parte de la ola genómica se organizaron para secuenciar, mediante el uso de una técnica desarrollada por Dias-Neto y Simpson, segmentos internos de genes que se encuentran activos en los tumores mamarios, de intestino y de cabeza y cuello, entre otros, con énfasis en los más frecuentes en la población brasileña. Los datos de 280 mil secuencias se archivaron en un banco público de informaciones génicas, el GenBank, y se utilizaron para colaborar con la identificación de los genes en los cromosomas humanos secuenciados por los grupos del Proyecto Genoma Humano.
Los reportajes de tapa de las ediciones nº 50, 51, 68 y 97 (a partir de la izq.) de Pesquisa FAPESP versaron sobre proyectos ligados a la secuenciación de genomas
A la secuenciación del genoma de la Xyllela y el del cáncer le siguió en Brasil la de otros patógenos vegetales (el de la bacteria Xanthomonas citri) y humanos (el de la bacteria Leptospira sp y el del parásito Schistosoma mansoni), aparte del genoma de la vaca. También se secuenciaron los genes expresados en la caña de azúcar, lo que hizo posible la producción de una planta transgénica resistente a plagas y herbicidas, y los del eucalipto. A partir de ese esfuerzo, surgieron empresas de biotecnología tales como Scylla, Alellyx y CanaVialis, las dos últimas adquiridas por la multinacional Monsanto y posteriormente cerradas. No obstante, desde la perspectiva de Perez, “uno de los legados más importantes de los genomas que la Fundación coordinó fue el desarrollo de la bioinformática en Brasil”.
Antes de iniciarse las secuenciaciones a mayor escala, el bioinformático se capacitaba en forma autodidacta, comenta João Meidanis, de la Unicamp, quien se graduó en matemática y optó por la bioinformática cuando hacía su doctorado en Estados Unidos, etapa en la que tomó parte en el análisis del genoma de la bacteria Escherichia coli. Desde entonces, surgieron carreras específicas para bioinformáticos en algunas universidades brasileñas. “La comunidad creció, aunque no al ritmo que se esperaba, y la bioinformática sigue siendo un problema para el análisis de la información genómica”, informa Meidanis, quien también dirige la empresa Scylla Informática.
Arruda, de la Unicamp, analiza la era de la secuenciación de genomas como un hito para la ciencia brasileña. “Aprendimos a trabajar en red y a administrar grandes grupos en forma eficiente”, comenta. “También establecimos una interacción importante entre las universidades y las empresas del sector privado”.
“Si no hubiésemos desarrollado esos proyectos en aquel momento, hoy en día tal vez no estaríamos listos para usar esta tecnología que se ha vuelto algo habitual”, comenta la bióloga Marie-Anne van Sluys, de la USP. En la actualidad, la investigadora coordina la participación brasileña en una iniciativa bastante más ambiciosa: el Earth Biogenome Project, que al cabo de 10 años contempla secuenciar el genoma de todas las especies de plantas y animales (unicelulares o pluricelulares) conocidas. Será un trabajo hercúleo. Se conocen alrededor de 2,3 millones de especies, aunque se estima que, en total, serían entre 10 y 15 millones.
This article may be republished online under the CC-BY-NC-ND Creative Commons license. The Pesquisa FAPESP Digital Content Republishing Policy, specified here, must be followed. In summary, the text must not be edited and the author(s) and source (Pesquisa FAPESP) must be credited. Using the HTML button will ensure that these standards are followed. If reproducing only the text, please consult the Digital Republishing Policy.