Unos 3 mil científicos y estudiantes de computación suscribieron en el mes de mayo un manifiesto comprometiéndose a no enviar artículos a un periódico científico que será lanzado al comienzo de 2019 ni participar en su proceso de revisión por pares. La revista en cuestión es Nature Machine Intelligence, del grupo editorial Springer Nature, que se propone divulgar estudios sobre inteligencia artificial, aprendizaje de máquina y robótica. La promesa de boicot se basa en un argumento sencillo: la producción científica en ciencias de la computación y particularmente en inteligencia artificial adopta un modelo peculiar de difusión en el cual los nuevos hallazgos se divulgan y debaten en conferencias y luego se los archiva en repositorios de acceso abierto, siendo el ArXiv uno de los destinos más frecuentes de los manuscritos. Este paradigma se opone al sistema tradicional de la comunicación científica, en el cual el acceso se encuentra disponible para quienes estén dispuesto a pagar para leer, y también a un modelo más moderno que fue ganando espacio en los últimos tiempos, en el cual el acceso es abierto, pero el autor paga un canon para financiar la publicación.
“No vislumbramos ningún papel en el futuro de la investigación en aprendizaje de máquinas, para las revistas de acceso cerrado o que cobren aranceles por derechos de autor”, informa el manifiesto. “Al contrario, recibiríamos de buen grado nuevas conferencias y revistas cuya publicación no tenga costo”. La declaración fue firmada tanto por científicos ligados a institutos de investigación, entre los cuales figuran la Universidad Harvard y el Massachusetts Institute of Technology (MIT), de Estados Unidos, como por expertos vinculados a empresas tales como Google, Microsoft, Facebook e IBM. La ausencia de personalidades de Apple fue lamentada.
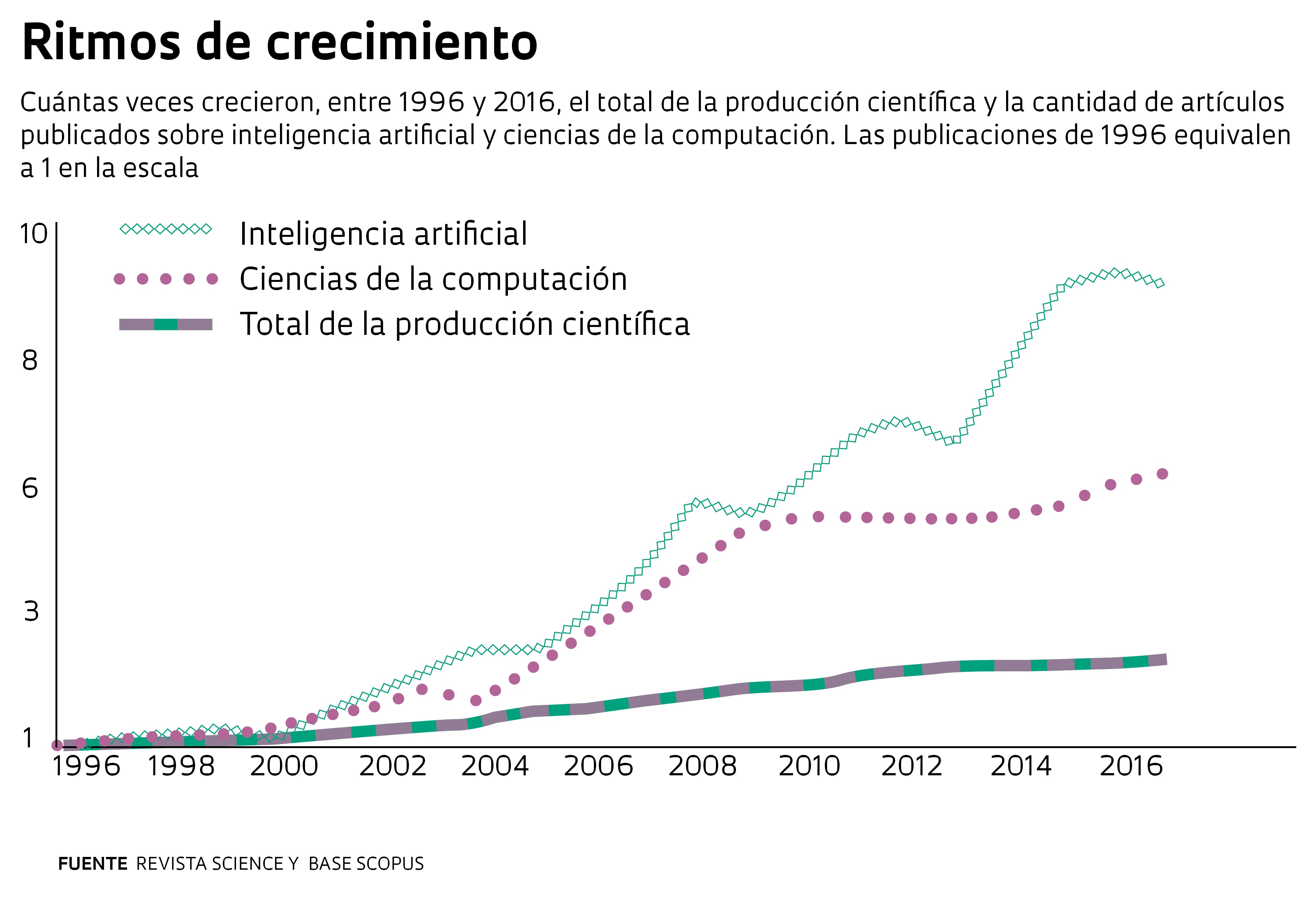
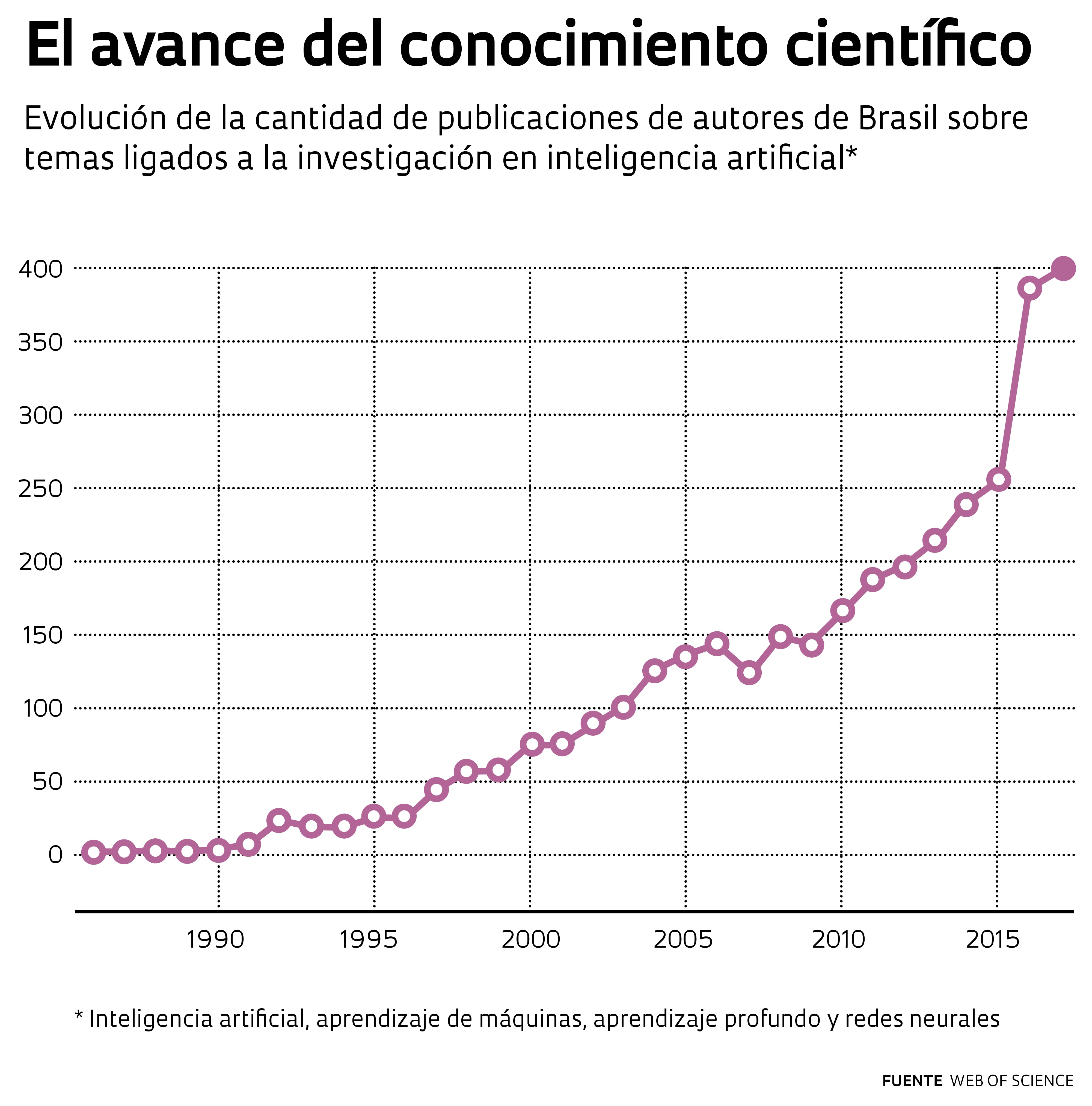
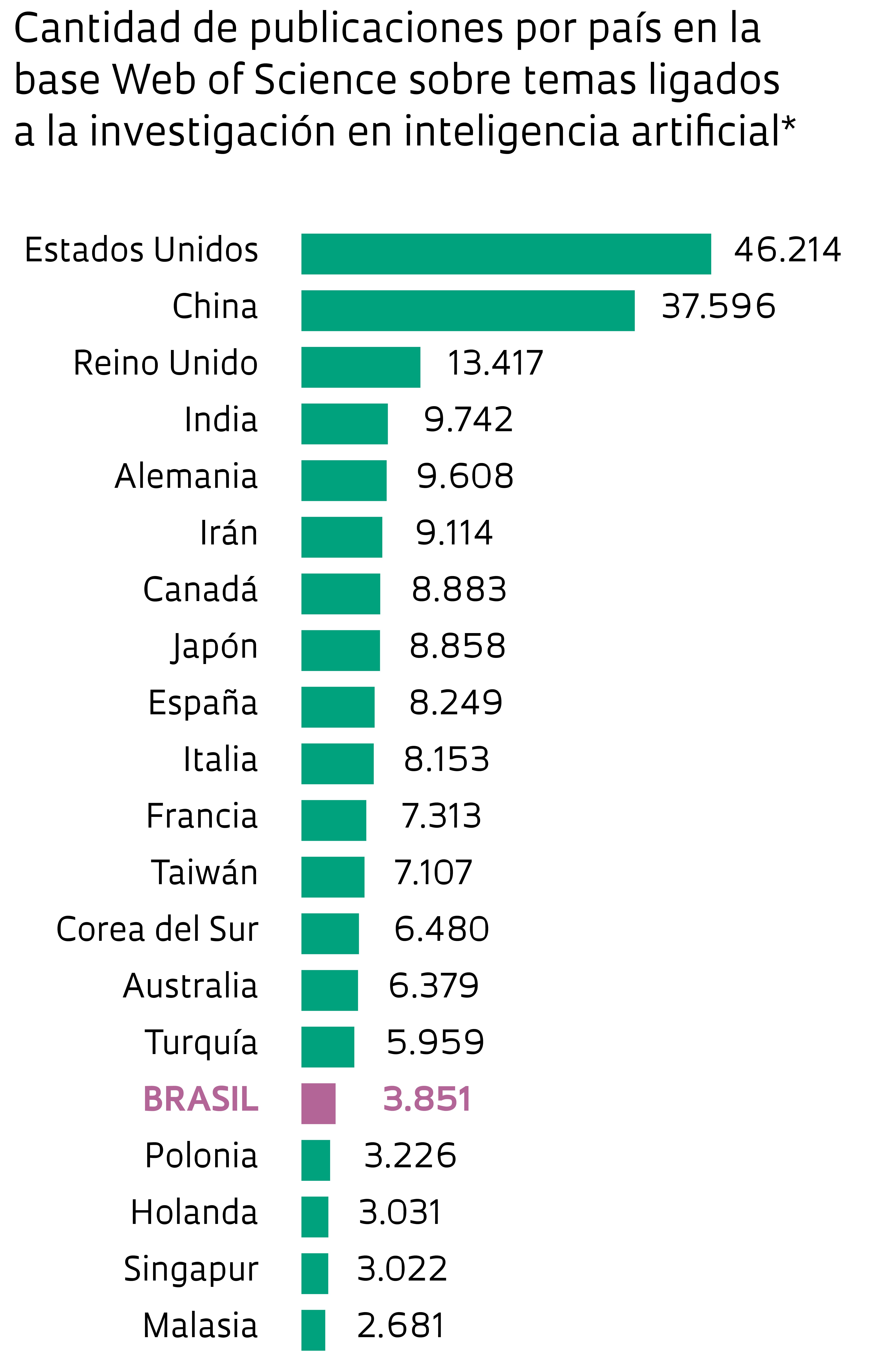
Entre los signatarios, se destacan nombres tales como los de los científicos de la computación Yann LeCunn, docente de la Universidad de Nueva York y director de la división de investigación en inteligencia artificial de Facebook, y Yoshua Bengio, de la Universidad de Montreal, en Canadá, pioneros de la investigación en redes neuronales. “La comunidad de aprendizaje de máquina ha efectuado una gran labor al publicar investigaciones en acceso abierto; revertir esa tendencia apelando a un modelo cerrado no parece que sea una buena idea”, dijo, según la revista Forbes, Jeff Dean, director de Google AI, la rama de investigación de Google en inteligencia artificial, otro de los que firmó la declaración. Según datos recabados de la base Scopus y recopilados por la revista Science, la cantidad de trabajos científicos en inteligencia artificial se multiplicó por 10 entre 1996 y 2016, por encima del promedio de la ciencia de la computación, que creció seis veces en el mismo período. En Brasil, la tendencia es similar: hay científicos que publican en el área desde la década de 1990. Y conformaron un bloque de investigación responsable de una producción que duplicó largamente su tamaño entre 2010 y 2016 (observe el gráfico en esta página).
El responsable del manifiesto, el científico de la computación Thomas Dietterich, quien es profesor emérito de la Universidad del Estado de Oregón, en Estados Unidos, utilizó su cuenta en Twitter para invitar a colegas a suscribir la declaración. Como respuesta recibió un tuit de la propia revista Nature Machine Intelligence en un tono conciliador: “Creemos que Nature Machine Intelligence puede coexistir y proveer un servicio –para aquellos que estén interesados–, conectando diversos campos, ofreciendo un canal para trabajos interdisciplinarios y llevando a cabo un riguroso proceso de evaluación por pares”. La vocera de Springer Nature en Londres, Susie Winter, divulgó un comunicado en defensa del modelo: “Creemos que la manera más justa de producir revistas altamente selectivas como ésta es garantizar su sostenibilidad a largo plazo para una comunidad lo más amplia posible consiste en repartir los costos entre muchos lectores”.
El manifiesto tuvo gran repercusión, porque movilizó a un campo emergente de la investigación científica en defensa del acceso abierto y también porque se opone a uno de los mayores grupos de comunicación científica del mundo. Pero no sorprende a aquellos que siguen la evolución del conocimiento en inteligencia artificial y al ambiente en que la misma se produce. En 2001 hubo un round previo de este embate cuando la científica de la computación Leslie Kaelbling, del MIT, lanzó el periódico de acceso abierto Journal of Machine Learning Research (JMLR) como alternativa a la prestigiosa revista Machine Learning, de Kluwer Academic Press, de acceso restringido. En aquella época, buena parte del consejo editorial de Machine Learning renunció y migró para la JMLR.
La percepción de que el proceso tradicional de publicación científica era lento para un campo del conocimiento en efervescencia llevó a los científicos de la computación a adoptar un modelo en el cual las conferencias y los repositorios de acceso abierto tienen un peso preponderante y la revisión por pares está abierta al aporte de cualquier científico y se realiza luego de la divulgación de los resultados. Ese modelo continúa en evolución. En 2013, el informático teórico Andrew McCallum, de la Universidad de Massachusetts, en Amherst, Estados Unidos, creó el sitio web Open Review, por medio del cual los autores pueden publicar manuscritos presentados en conferencias e invitar a sus colegas a comentarlos. En poco tiempo, las principales conferencias sobre inteligencia artificial adoptaron la utilización de los servicios de ese portal.
 El presidente de la Asociación Brasileña de Editores Científicos, Rui Seabra Ferreira Júnior, dice que los modelos de publicación científica atraviesan una etapa de transición y aún no hay claridad al respecto de su devenir. “La revisión por pares existe desde hace más de 300 años y no se vislumbra que vaya a perder importancia. Pero hay algunos campos disciplinarios más teóricos, tales como algunas áreas de la física y de las ciencias de la computación, donde es posible que un investigador presente conceptos nuevos en un repositorio de acceso abierto y dejarlos abiertos al debate entre colegas, cabiéndoles a ellos convalidarlo o no”, expresa. “En tanto, en áreas aplicadas, la revisión por pares resulta esencial. Obsérvese el caso de la biología o de la medicina: sería necesario que los colegas reprodujeran los experimentos descritos en repositorios que los convalidaran, algo que sería inviable”.
El presidente de la Asociación Brasileña de Editores Científicos, Rui Seabra Ferreira Júnior, dice que los modelos de publicación científica atraviesan una etapa de transición y aún no hay claridad al respecto de su devenir. “La revisión por pares existe desde hace más de 300 años y no se vislumbra que vaya a perder importancia. Pero hay algunos campos disciplinarios más teóricos, tales como algunas áreas de la física y de las ciencias de la computación, donde es posible que un investigador presente conceptos nuevos en un repositorio de acceso abierto y dejarlos abiertos al debate entre colegas, cabiéndoles a ellos convalidarlo o no”, expresa. “En tanto, en áreas aplicadas, la revisión por pares resulta esencial. Obsérvese el caso de la biología o de la medicina: sería necesario que los colegas reprodujeran los experimentos descritos en repositorios que los convalidaran, algo que sería inviable”.
El físico Paul Ginsparg, investigador de la Universidad Cornell y fundador del repositorio ArXiv, alabó el manifiesto de los científicos de la computación, pero se mostró escéptico en cuanto a su capacidad para influir en el modelo de publicación científica como un todo. “Personalmente, no tengo ninguna animosidad contra el modelo de suscripción”, declaró en la revista Science. Él considera que los firmantes del manifiesto tienen un panorama bastante poco realista acerca de la posibilidad de publicar con costo cero. “Los servidores de repositorio son baratos, aunque un control de calidad sistemático requiere de mano de obra intensiva y eso cuesta dinero”.
Un sistema recopila datos sobre la producción de investigadores brasileños en subáreas de la ciencia de la computación
Rodrigo de Oliveira Andrade
Científicos de las universidades federales de Minas Gerais (UFMG) y de Uberlândia (UFU) crearon un sistema que provee datos comparativos sobre la producción de los departamentos de ciencia de la computación de instituciones de educación superior de Brasil. El sistema que salió al ruedo en enero, denominado CSIndex, ofrece informaciones que pueden ser de utilidad tanto para evaluar el desempeño de grupos de investigación como para orientar a los estudiantes en la elección de cursos de maestría y doctorado. El servicio recopila y organiza el total de la producción de los departamentos en 16 subáreas, generando un puntaje para cada uno. El Instituto de Matemática y Estadística de la Universidad de São Paulo (IME-USP) fue calificado con el puntaje más alto en el área de inteligencia artificial. En tanto, en ingeniería de software, la Universidad Federal de Pernambuco (UFPE) sacó la mejor nota, mientras que el Departamento de Ciencias de la Computación de la UFMG obtuvo la calificación más alta en el área de banco de datos.
La recolección de las informaciones se realiza por medio del seguimiento de los artículos presentados en conferencias indexadas en bases de datos internacionales. En el área de las ciencias de la computación, la publicación de trabajos en conferencias suele ser más importante que la difusión de artículos en revistas científicas. El CSIndex monitorea artículos publicados en las crónicas de 162 conferencias, distribuidas en subáreas tales como ingeniería de software, lenguajes de programación, arquitectura de computadoras y bancos de datos.
El sistema utiliza un algoritmo concebido para recuperar información de la Digital Bibliography & Library Project (DBLP), uno de los principales repositorios bibliográficos de ciencias de la computación, alojado en la Universidad de Tréveris, en Alemania. El DBLP tiene indexados más de 3 millones de artículos de 1,7 millones de autores y se actualiza mensualmente. “El CSIndex filtra los trabajos cuyos autores son brasileños, y los clasifica según las subáreas referidas”, explica el científico de la computación Marco Tulio Valente, de la UFMG, uno de los creadores del sistema, junto a su colega con la misma profesión Klérisson Paixão, de la UFU. A continuación, calcula el puntaje para cada departamento. El CSIndex monitorea la producción científica de 818 científicos de la computación de universidades públicas y privadas, y de institutos federales de todo el país.
Las conferencias con mayor prestigio de ciencias de la computación disponen de un proceso de selección bastante riguroso y por lo general, aceptan menos del 20% de los artículos remitidos. Los trabajos publicados en 34 de esas conferencias más disputadas fueron calificadas con 1, mientras que los divulgados en el resto obtienen un puntaje de 0,33. “El puntaje de cada departamento es el resultado de la combinación del número de artículos publicados por los investigadores en conferencias ‘top’ y en el resto de los congresos monitoreados por el CSIndex”, explica Valente.
La idea, según él, es que el CSIndex se constituya como una plataforma independiente, que sirva como complemento para los sistemas corrientes de evaluación, como el que realiza cada cuatro años la Coordinación Nacional de Perfeccionamiento del Personal de Nivel Superior (Capes), que monitorea la calidad de los programas de posgrado. De acuerdo con la idea del científico de la computación André Sampaio Gradvohl, de la Facultad de Tecnología de la Universidad de Campinas (Unicamp), es importante que el CSIndex tenga en cuenta a otros repositorios además del DBLP. “La ampliación del número de repositorios es recomendable para la consideración de trabajos publicados en periódicos científicos”, dice el investigador, quien no participó en la concepción del sistema.
Para el científico de la computación Filipe Saraiva, de la Universidad Federal de Pará, tampoco involucrado en la creación del CSIndex, la posibilidad de monitorear la calidad de la producción de los otros departamentos abre espacio para nuevas colaboraciones. “Es interesante analizar las mediciones relacionadas con las investigaciones en ciencias de la computación que se desarrollan en Brasil, todavía más, cuando las mismas se basan en un filtro que prioriza las publicaciones de alto impacto”, pondera.