 Los algoritmos están por todas partes. Cuando la bolsa sube o baja, generalmente están implicados. Según datos dados a conocer en 2016 por el Instituto de Investigación Económica Aplicada (Ipea), robots inversores programados para reaccionar instantáneamente ante determinadas situaciones son responsables de más del 40% de las decisiones de compra y venta en el mercado de acciones de Brasil, en tanto que en Estados Unidos ese porcentaje llega al 70%. El éxito de una simple búsqueda en Google depende de una de esas recetas escritas en el lenguaje de la programación computacional, que es capaz de filtrar en segundos miles de millones de páginas en la web: la importancia de una página, definida por un algoritmo, se basa en la cantidad y en la buena procedencia de enlaces que remiten a ella. En la frontera de la investigación en ingeniería automotriz, conjuntos de algoritmos utilizados por coches autónomos procesan informaciones captadas por cámaras y sensores, tomando instantáneamente las decisiones al volante sin intervención humana.
Los algoritmos están por todas partes. Cuando la bolsa sube o baja, generalmente están implicados. Según datos dados a conocer en 2016 por el Instituto de Investigación Económica Aplicada (Ipea), robots inversores programados para reaccionar instantáneamente ante determinadas situaciones son responsables de más del 40% de las decisiones de compra y venta en el mercado de acciones de Brasil, en tanto que en Estados Unidos ese porcentaje llega al 70%. El éxito de una simple búsqueda en Google depende de una de esas recetas escritas en el lenguaje de la programación computacional, que es capaz de filtrar en segundos miles de millones de páginas en la web: la importancia de una página, definida por un algoritmo, se basa en la cantidad y en la buena procedencia de enlaces que remiten a ella. En la frontera de la investigación en ingeniería automotriz, conjuntos de algoritmos utilizados por coches autónomos procesan informaciones captadas por cámaras y sensores, tomando instantáneamente las decisiones al volante sin intervención humana.
Aunque influyen incluso en las actividades cotidianas más prosaicas, como la búsqueda de atajos en el tránsito con la ayuda de aplicaciones de celulares, los algoritmos suelen ser vistos como objetos intangibles por la población en general, que siente sus efectos, pero no conoce ni comprende su formato y su modo de acción. Un algoritmo no es más que una secuencia de etapas para resolver un problema o realizar una tarea de forma automática, ya sea que tenga tan sólo una decena de líneas de programación o millones de ellas apiladas en una especie de pergamino virtual. “Es el átomo de cualquier proceso computacional”, define el científico de la computación Roberto Marcondes Cesar Junior, investigador del Instituto de Matemática y Estadística de la Universidad de São Paulo (IME-USP).
Tómese el ejemplo de la secuencia de pasos realizada por el algoritmo de Facebook. La elección que aparecerá en el feed de noticias de un usuario depende, en primer lugar, del conjunto de publicaciones producidas o que circulan entre sus amigos. En líneas generales, el algoritmo analiza esas informaciones, descarta publicaciones denunciadas como de contenido violento o impropio, aquéllas que parezcan spam o las que tengan un lenguaje identificado como “caza clics”, con exageraciones de marketing. Finalmente, el algoritmo le asigna una calificación a cada una de las publicaciones con base en el historial de actividad del usuario, intentando suponer cuánto sería susceptible a que le guste o comparta aquella información. Recientemente, el algoritmo fue modificado para reducir el alcance de publicaciones oriundas de sitios de noticias.
La construcción de un algoritmo sigue tres etapas (vea la infografía en la página 19). La primera consiste en identificar con precisión el problema que ha de resolverse, y encontrarle una solución. En esa etapa, el científico de la computación necesita la orientación de profesionales que entiendan la tarea por ejecutarse. Pueden ser médicos, en el caso de un algoritmo que analiza estudios por imágenes; sociólogos, si el objetivo es identificar estándares de violencia en regiones de una ciudad; o psicólogos y demógrafos en la construcción, por ejemplo, de una aplicación de búsqueda de pareja. “El desafío es mostrar que la solución del problema existe desde el punto de vista práctico, que no se trata de un problema de complejidad exponencial, para el cual el tiempo necesario para producir una respuesta puede crecer exponencialmente, volviéndolo impracticable”, explica el científico de la computación Jayme Szwarcfiter, investigador de la Universidad Federal de Río de Janeiro (UFRJ).
 La segunda etapa todavía no implica operaciones matemáticas: consiste en describir la secuencia de pasos en el idioma corriente, para que todos puedan comprender. Por último, esa descripción es traducida a algún lenguaje de programación. Solo así la computadora logra entender los comandos –que pueden ser órdenes sencillas, operaciones matemáticas y hasta algoritmos dentro de algoritmos–, y todo en una secuencia lógica y precisa. En ese momento entran en acción los programadores, profesionales incumbidos de escribir los algoritmos o fragmentos de ellos. Según la complejidad de la misión, equipos extensos de programadores trabajan en conjunto y se distribuyen tareas.
La segunda etapa todavía no implica operaciones matemáticas: consiste en describir la secuencia de pasos en el idioma corriente, para que todos puedan comprender. Por último, esa descripción es traducida a algún lenguaje de programación. Solo así la computadora logra entender los comandos –que pueden ser órdenes sencillas, operaciones matemáticas y hasta algoritmos dentro de algoritmos–, y todo en una secuencia lógica y precisa. En ese momento entran en acción los programadores, profesionales incumbidos de escribir los algoritmos o fragmentos de ellos. Según la complejidad de la misión, equipos extensos de programadores trabajan en conjunto y se distribuyen tareas.
En su origen, los algoritmos son sistemas lógicos tan antiguos como la matemática. “La expresión viene de la latinización del nombre del matemático y astrónomo árabe Muḥammad al-Juarismi, quien en el siglo IX escribió trabajos de referencia sobre álgebra”, explica la científica de la computación Cristina Gomes Fernandes, docente del IME-USP. Y asumieron nuevos propósitos durante la segunda mitad del siglo pasado con el desarrollo de las computadoras, por medio de ellos, fue posible crear rutinas para que las máquinas trabajen. La combinación de los factores explica por qué sus aplicaciones en el mundo real se vienen multiplicando y los algoritmos se han vuelto la base del desarrollo de software complejos. El primero fue la ampliación de la capacidad de procesamiento de las computadoras, que aceleraron la velocidad de la ejecución de tareas complejas. El segundo fue el advenimiento de la inteligencia de datos, el abaratamiento de la recolección y almacenado de cantidades gigantescas de información, que les dio a los algoritmos la posibilidad de identificar patrones imperceptibles a la mirada humana en actividades de todo tipo. La manufactura avanzada o Industria 4.0, con su promesa de ampliar la productividad de líneas de producción, depende de algoritmos de inteligencia artificial para monitorear plantas industriales en tiempo real y tomar decisiones sobre recomposición de existencias, logística y paradas de mantenimiento.
Uno de los efectos de la diseminación de los algoritmos en la computación fue el impulso a la inteligencia artificial, un campo de estudio creado en la década de 1950 que desarrolla mecanismos capaces de simular el razonamiento humano. Con cálculos computacionales cada vez más veloces y archivos de información con los cuales es posible efectuar comparaciones estadísticas, las máquinas adquirieron la capacidad de modificar su funcionamiento a partir de experiencias acumuladas y mejorar su desempeño, en un proceso asociativo que mimetiza el aprendizaje.
La capacidad de las computadoras para vencer a los humanos en juegos de mesa muestra cómo ese campo ha evolucionado. En 1997, la supercomputadora Deep Blue, de IBM, logró por primera vez vencer al entonces campeón mundial de ajedrez, el ruso Garri Kaspárov. Capaz de simular aproximadamente 200 millones de posiciones del ajedrez por segundo, la máquina anteveía el comportamiento del adversario varias jugadas adelante. Pero esa estrategia no funcionaba en un juego de origen chino, el go, porque los lances posibles eran demasiado numerosos como para anticipárselos: la lista de posibilidades es mayor que la cantidad de átomos en el universo. Pues bien, en marzo de 2016, la barrera del go fue vencida: el programa AlphaGo, creado por DeepMind, subsidiaria de Google, logró superar al campeón mundial del juego, el surcoreano Lee Sedol.
 En lugar de considerar millones de posibilidades, el algoritmo del programa buscó una estrategia más restringida. Fue abastecido con datos de partidos de go disputados entre los mejores competidores, hizo un análisis estadístico identificando las jugadas más comunes y eficientes y pasó a trabajar con un conjunto pequeño de variables, pronto venciendo a los jugadores humanos. Pero la hazaña no se frenó allí. El año pasado, DeepMind presentó un nuevo programa, el AlphaGo Zero, que superó al AlphaGo. Y esta vez la máquina no aprendió con seres humanos, sino tan sólo con la versión anterior del programa.
En lugar de considerar millones de posibilidades, el algoritmo del programa buscó una estrategia más restringida. Fue abastecido con datos de partidos de go disputados entre los mejores competidores, hizo un análisis estadístico identificando las jugadas más comunes y eficientes y pasó a trabajar con un conjunto pequeño de variables, pronto venciendo a los jugadores humanos. Pero la hazaña no se frenó allí. El año pasado, DeepMind presentó un nuevo programa, el AlphaGo Zero, que superó al AlphaGo. Y esta vez la máquina no aprendió con seres humanos, sino tan sólo con la versión anterior del programa.
Las aplicaciones prácticas de este tipo de tecnología son cada vez más frecuentes. Algoritmos de inteligencia artificial desarrollados por el científico de la computación Anderson de Rezende Rocha, docente del Instituto de Computación de la Universidad de Campinas (Unicamp), han auxiliado investigaciones a cargo de la Policía Federal de Brasil. De Rezende Rocha se especializó en crear herramientas de computación forense e inteligencia artificial capaces de detectar sutilezas en documentos digitales muchas veces imperceptibles a simple vista. “La tecnología ayuda al perito, por ejemplo, a confirmar si determinada foto o video relacionados con un delito son genuinos”, dice el investigador.
Uno de los casos en que se están utilizando los algoritmos es el de la automatización de investigaciones sobre pornografía infantil. Constantemente, los policías incautan grandes cantidades de fotos y videos en las computadoras de sospechosos. De existir archivos con pornografía infantil, el algoritmo ayuda a encontrarlos. “Expusimos el robot a horas de videos pornográficos de internet para extraer datos. Tuvimos que enseñarle qué es pornografía”, comenta De Rezende Rocha. Después, para que pudiera distinguir la presencia de niños o niñas, el algoritmo tuvo que “mirar” contenidos de pornografía infantil incautados. “Esa etapa estuvo a cargo estrictamente de técnicos de la policía. Desde la Unicamp no tuvimos acceso a ese material”, destaca. De Rezende Rocha comenta que el análisis de los archivos se hacía sin demasiada automatización. “Al hacer ese proceso más eficiente, los investigadores de la Policía Federal ganaron tiempo y capacidad para analizar mayores cantidades de datos”.
Muchos científicos de la computación trabajan con propiedades matemáticas, teoremas y preguntas lógicas relacionadas con algoritmos, independientemente de la perspectiva de aplicaciones inmediatas. En muchas situaciones que requieren algoritmos, los únicos algoritmos conocidos son muy ineficientes, pues no funcionan, en la práctica, con grandes masas de datos. Algunos ejemplos de ello son la factorización de números enteros en primos (con gran importancia en criptografía) y el ruteo de un robot soldador por varios puntos de soldadura. Existe una pequeña esperanza de encontrar algoritmos eficientes para resolver esos problemas. La formulación precisa de esto es la pregunta acerca de “las clases de complejidad P y NP”, considerada, al mismo tiempo, uno de los mayores retos de la computación y de la matemática.
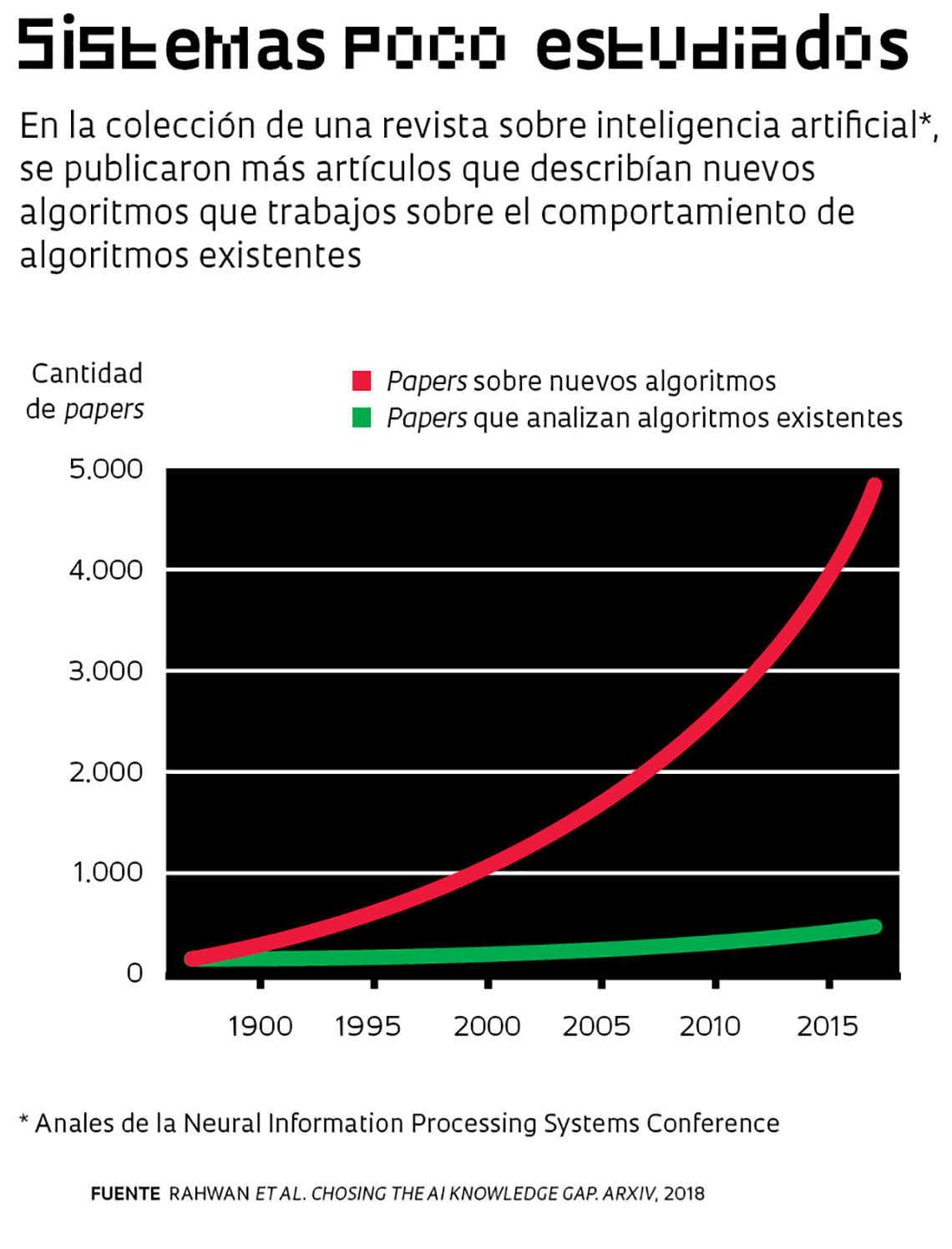
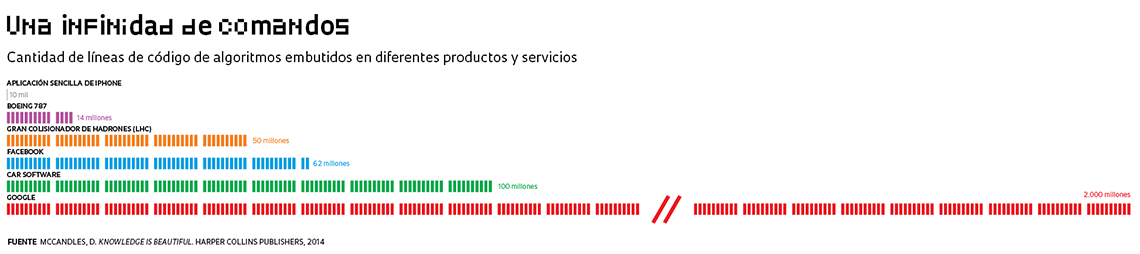
Aunque existe más programación que ciencia básica en el desarrollo de buena parte de los algoritmos utilizados en el cotidiano, avances en conocimiento de frontera son esenciales para que nuevas aplicaciones puedan se explotadas en el futuro. Marcondes Cesar, de la USP, coordina un proyecto de visión computacional, un tipo de inteligencia artificial que logra extraer información de imágenes simulando el funcionamiento de la visión humana. Esta técnica está siendo incorporada en distintos sectores, con énfasis en la emisión de diagnósticos médicos. “La visión computacional permite detectar anomalías con mayor precisión y evaluar sutilezas en imágenes de resonancia magnética, por ejemplo.”
Este proyecto, una alianza con la Facultad de Medicina y el Instituto de Niños del Hospital de Clínicas de la USP, apunta a crear un modelo matemático que permita efectuar un análisis más preciso del hígado y del cerebro de recién nacidos. Normalmente, la interpretación de imágenes generadas mediante resonancia magnética se basa en modelos creados en otros países para hombres adultos y blancos, lo que puede crear diagnósticos imprecisos en recién nacidos. Pero, para que esto sea viable, es necesario resolver problemas teóricos. “Todavía no sabemos si lograremos obtener un algoritmo cuya aplicación sea eficiente. Estamos aún estudiando propiedades con base en la teoría de los grafos”, dice, en referencia a la rama de la matemática que estudia las relaciones entre objetos de un determinado conjunto, asociándolos por medio de estructuras llamadas grafos.
El impacto de los algoritmos es objeto de análisis de otros campos del conocimiento. “Los algoritmos ya están desempeñando un papel moderador. Google, Facebook y Amazon conquistaron un poder extraordinario sobre lo que encontramos hoy en el campo cultural”, asevera Ted Striphas, docente de historia de la cultura y la tecnología en la Universidad de Colorado, Estados Unidos, y autor del libro Algorithmic culture (2015), donde examina la influencia de esas herramientas. El antropólogo estadounidense Nick Seaver, investigador de la Universidad de Tufts, en Estados Unidos, se dedica actualmente a un proyecto basado en investigación etnográfica y entrevistas con creadores de algoritmos de recomendación de temas musicales en servicios de transmisión en directo. Su interés es comprender cómo esos sistemas se diseñan para atraer a usuarios y llamarles la atención, trabajando en la interfaz de áreas como aprendizaje de máquinas y publicidad en línea. “Los mecanismos que controlan la atención y sus mediaciones técnicas se han convertido en objeto de gran preocupación. La formación de burbujas de interés y de opinión, las fake news y la distracción en el campo político se les atribuyen a tecnologías diseñadas para manipular la atención de los usuarios”, explica.
Los sistemas de recomendación controlados por algoritmos se han vuelto piezas claves en la industria del entretenimiento en internet. En un artículo publicado en 2015 en el periódico científico ACM Transactions on Management Information Systems, el ingeniero electrónico mexicano Carlos Gómez Uribe describió el funcionamiento de conjuntos de algoritmos desarrollados por el servicio de streaming Netflix que elaboran rankings personalizados de series y películas compatibles con el perfil de los usuarios. El desafío es hacer que el cliente elija un programa en menos de 90 segundos; después de ese tiempo la tendencia es frustrarse y perder interés. El éxito del ranking valorizó el pase profesional de Gómez Uribe, quien en 2017 asumió como coordinador de algoritmos y de tecnologías de productos de internet de Facebook.
La influencia y el poder de las grandes empresas de internet no dependen sólo de la creatividad de sus programadores. Tienen que ver, igualmente, con el acceso a los macrodatos que acumularon y que son procesado por sus algoritmos, generando informaciones valiosas. “Qué impide que otra empresa desarrolle una aplicación como la de Uber? Eso ya se ha hecho. Pero los datos de los que dispone Uber sobre el tránsito y el comportamiento de los usuarios acumulados a lo largo del tiempo pertenecen sólo a la empresa y son valiosos”, dice Marcondes Cesar, de la USP.
El escándalo que implicó la filtración de datos de usuarios de Facebook, que le hizo perder a la empresa 49 mil millones de dólares de su valor el mes pasado, reveló una vulnerabilidad que no se imaginaba que fuera común: algoritmos utilizados por la empresa Cambridge Analytica lograron obtener datos del comportamiento de 50 millones de usuarios de Facebook y los utilizaron para orientar campañas en las redes sociales por la salida del Reino Unido de la Unión Europea y a favor de la candidatura de Donald Trump a la presidencia de los Estados Unidos, que terminaron victoriosas. El caso de Facebook es ejemplar de los desafíos éticos generados por la diseminación del uso de algoritmos, aunque la filtración y el uso indebido de los datos sean tan sólo una parte del problema. La oferta de datos se ha vuelto tan importante en la construcción de algoritmos como el desafío de programarlos. “Analizar las características de los datos ofrecidos es fundamental a la hora de construir un algoritmo, porque descuidos en ese momento pueden provocar sesgos en los resultados”, afirma Marcondes Cesar.
También es común que, al guiarse por comportamientos humanos, los algoritmos reproduzcan prejuicios. El Cloud Natural Language API, una herramienta creada por Google que revela la estructura y el significado de textos por medio del aprendizaje de máquinas, desarrolló tendencias prejuiciosas. Un test realizado por el sitio web estadounidense Motherboard mostró que, al analizar párrafos de textos para determinar si presentaban sentidos “positivos” o “negativos”, el algoritmo clasificó declaraciones del tipo “yo soy homosexual” y “yo soy una mujer negra gay” como negativas. “Los programadores que crean algoritmos inteligentes deben estar conscientes de que su trabajo tiene implicaciones sociales y políticas”, dice Nick Seaver, de la Universidad de Tufts. Algunos carreras de grado y posgrado en ciencias de la computación ya ofrecen asignaturas que abordan la ética computacional. Es el caso de USP, en Brasil, y de la Universidad Harvard y del Instituto de Tecnología de Massachusetts (MIT), en Estados Unidos.
Otro debate candente se relaciona con la transparencia de algoritmos avanzados. Ocurre que detalles del desarrollo de esas herramientas frecuentemente son mantenidos en secreto por sus creadores. En otros casos, la complejidad del código es tan grande que un observador no logra entender cómo produce una decisión y cuáles son sus implicaciones. Sistemas opacos al escrutinio externo se ganan el apodo de “algoritmos caja negra”. La discusión cobró impulso con la investigación sobre una herramienta utilizada experimentalmente en el poder judicial estadounidense, el Compas (Correctional Offender Management Profiling for Alternative Sanctions) – su algoritmo sugiere la pena del condenado y además vaticina sobre la posibilidad de reincidencia. Este estudio, realizado en 2016 por la organización ProPublica, reveló que, al pasar por el cribo de Compas, los acusados negros tienen 77% más probabilidades de ser clasificados como posibles reincidentes que acusados blancos. Northpointe, la empresa privada que creó el algoritmo, se niega a divulgar el código de Compas. “Algoritmos de dimensión pública no deben crearse ni desarrollarse sin la participación de los gestores y administradores públicos, pues no son neutrales”, destaca Sérgio Amadeu da Silveira, investigador del Centro de Ingeniería, Modelado y Ciencias Sociales Aplicadas de la Universidad Federal del ABC (UFABC).
En 2017, Kate Crawford, líder de investigación de Microsoft Research, y Meredith Whittaker, directora del Open Research, vinculado a Google, fundaron el AI Now Institute, una organización dedicada a investigar el impacto de la inteligencia artificial en la sociedad. Con sede en la Universidad de Nueva York, Estados Unidos, la institución invierte en un abordaje que integra análisis de científicos de la computación, abogados, sociólogos y economistas. En octubre, divulgó un informe con orientaciones sobre el uso de algoritmos de inteligencia artificial. Una de las recomendaciones apunta que órganos públicos responsables de sectores tales como justicia, salud, asistencia social y educación eviten usar algoritmos cuyos modelos no se conozcan. El documento recomienda que los algoritmos caja negra pasen por auditorías públicas y pruebas de validación como una forma de instituir mecanismos de corrección cuando sea necesario.
Liberar a los seres humanos de actividades repetitivas es otro presagio de los algoritmos de inteligencia artificial, y el debate sobre las implicaciones de los software inteligentes en el mercado de trabajo cobra cuerpo. En el informe “El futuro del empleo”, publicado en 2013 por los economistas Carl Frey y Michael Osborne, de la Oxford Martin School, se evaluó que algoritmos sofisticados pueden sustituir a 140 millones de profesionales que actúan en actividades intelectuales en todo el mundo. En el documento se mencionan ejemplos como la creciente automatización de las decisiones tomadas en el mercado financiero e incluso el impacto en el trabajo de los ingenieros de software: por medio del aprendizaje de máquinas, la programación puede perfeccionarse y acelerarse con la ayuda de algoritmos. “Actividades intelectuales procedimentales, que implican repetición de estándares, como traducir documentos, tienen una posibilidad enorme de ser ejecutadas por algoritmos”, asevera Sérgio Amadeu, de UFABC. El debate sobre los efectos colaterales de la inteligencia artificial es necesario, afirma Marcondes Cesar, de USP, pero por ahora está lejos de contraponerse a las notables contribuciones de los algoritmos en la solución de problemas de todo tipo.

Hoobox Robotics
Un algoritmo traduce expresiones del rostro en comandos para mover una silla de ruedas motorizadaHoobox RoboticsHoobox Robotics, una empresa fundada en 2016 por investigadores de Unicamp, desarrolló un sistema para su instalación en cualquier silla de ruedas motorizada y permite que personas tetrapléjicas puedan controlar el vehículo utilizando solamente sus expresiones faciales. El algoritmo presente en el software, llamado Wheelie, traduce hasta 11 expresiones faciales, como una sonrisa y una ceja levantada, en comandos para seguir adelante, retroceder y doblar a la derecha o a la izquierda. El programa está siendo probado en 39 pacientes en los Estados Unidos, donde la empresa mantiene una unidad de investigación en el laboratorio de Johnson&Johnson, en Houston. El sistema utiliza una cámara 3D que capta decenas de puntos en el rostro.
“El usuario puede configurar un comando para cada expresión. Una sonrisa, por ejemplo, puede mover la silla hacia adelante, un beso, hacia atrás”, aclara el científico de la computación Paulo Gurgel Pinheiro, director de Hoobox. Para asimilar las principales expresiones, el algoritmo de Wheelie fue abastecido con un conjunto de datos faciales de 103 conductores de camión. “Firmamos una alianza con una compañía de transporte para instalar cámaras en camiones y registrar las impresiones faciales de los voluntarios a lo largo de tres meses”, explica Gurgel.
El objetivo de un proyecto ejecutado en el IME-USP en colaboración con el Laboratory of Image Data Science (LIDS) de la Unicamp consiste en perfeccionar el diagnóstico de parasitosis mediante el empleo de la visión computacional. El científico de la computación Marcelo Finger, del IME, está probando un algoritmo capaz de identificar parásitos procesando imágenes de láminas con heces de pacientes. “Ya hemos logrado identificar 15 parásitos en humanos y algunos en animales, tales como vacas, gatos y perros”, cuenta. En la actualidad, el diagnóstico se obtiene por el análisis de las heces en microscopio. “El profesional generalmente logra evaluar cerca de seis láminas a la vez.
La intención es automatizar este proceso”, afirma Finger. Parece sencillo; sin embargo, sabiendo que los algoritmos buscan identificar estándares, cualquier ruido pode volverse un obstáculo para los investigadores. “Una cosa es que el algoritmo logre identificar al parásito en la foto de un libro, otra es hacer lo mismo a partir de una imagen en la que el parásito está rodeado de suciedad”, hace la salvedad el investigador.

Projeta Sistemas
El sistema utiliza una técnica de visión computacional para estimar el peso del ganadoProjeta SistemasExisten algoritmos creados a medida para ayudar a los ganaderos. Projeta Sistemas, una startup localizada en Vitória (en el estado de Espírito Santo, Brasil), creó un sistema computacional llamado “Olho do Dono” [El Ojo del Dueño), que se basa en imágenes 3D para estimar el peso de un vacuno. “El proceso de pesaje de los animales es muy costoso y demorado, y comprende el desplazamiento del ganado, que puede quedar estresado e incluso perder peso”, explica el científico de la computación Pedro Henrique Coutinho, director de Projeta. El software se desarrolló con base en técnicas de visión computacional asociando las imágenes de las vacas tomadas por cámaras a sus respectivos pesos. Para ello fue necesario formar una base de datos robusta. “Acompañamos los pesajes de ganado en haciendas en todo Brasil. A partir del registro de miles de imágenes, pudimos desarrollar nuestro algoritmo”, dice Coutinho. El software empezó a desarrollarse en 2015 y empezará a comercializárselo en septiembre.
CrowdPet es una aplicación para smartphone que identifica animales perdidos creado por SciPet, empresa originada en la Unicamp. Por medio de un algoritmo, el sistema cruza datos referentes a fotos de animales perdidos registrados por sus dueños e imágenes de animales avistados en las calles por voluntarios. “La aplicación permite establecer una correspondencia entre ambas imágenes mediante métodos de reconocimiento visual, y efectúa el rastreo por geolocalización del sitio en donde se tomó la foto del animal perdido”, dice Fabio Rogério Piva, científico de la computación y director de SciPet. El Centro de Control de Zoonosis del municipio de Vinhedo, en el estado de São Paulo, empezó a utilizar esta aplicación el año pasado para registrar animales durante campañas de bienestar animal. SciPet desarrolló un prototipo capaz de diferenciar, con un 99% de acierto, perros y gatos de otros animales.